Maîtriser la programmation concurrente
- Quoi:
Cette compétence consiste à comprendre et à implémenter la programmation concurrente, qui permet l'exécution simultanée de plusieurs processus ou threads dans un programme. Elle implique la gestion efficace des ressources partagées, la prévention des conditions de compétition et des interblocages, et l'utilisation de mécanismes de synchronisation tels que les verrous, les sémaphores et les moniteurs pour assurer la cohérence et la performance des applications dans des environnements multicœurs ou distribués.
- Comment :
- En suivant une formation sur YouTube intitulée "JAVA - Threads" par Abdelwahab Naji. Cette formation a couvert divers aspects de la programmation multithread en Java, y compris la création et la gestion des threads, la synchronisation et la résolution des problèmes de concurrence. En appliquant les concepts appris à travers des projets pratiques. J'ai utilisé des méthodes comme start(), run(), join(), et sleep() pour gérer l'exécution des threads, et j'ai implémenté des techniques de synchronisation pour éviter les conditions de course.
-
J'ai fait de la recherche sur les mots-clés et les concepts clés de la programmation concurrente, tels que les threads, les verrous, les sémaphores, les moniteurs, les conditions de course, les interblocages, et les mécanismes de synchronisation. J'ai également étudié les meilleures pratiques et les modèles de conception pour la programmation concurrente :
- Thread : Une unité d'exécution dans un programme qui peut fonctionner indépendamment des autres threads.
- Processus : Une instance d'un programme en cours d'exécution avec sa propre mémoire et ses ressources.
- Synchronisation : La coordination de l'exécution des threads pour gérer l'accès aux ressources partagées.
- Semaphore : Un outil de synchronisation qui contrôle l'accès à une ressource partagée par plusieurs threads à l'aide d'un compteur.
- Concurrency (Concurrence) : La gestion de plusieurs tâches qui se chevauchent en temps.
- Parallelisme : L'exécution simultanée de plusieurs calculs ou processus, utilisant souvent plusieurs cœurs ou processeurs pour augmenter la performance.
-
Dans le projet Koloka, j'ai eu l'occasion de faire du parallélisme. Par exemple, en utilisant la méthode Promise.all() en JavaScript pour effectuer des requêtes simultanées à une API et traiter les réponses de manière asynchrone, ce qui a amélioré les performances globales de l'application.
const requests = [
fetch(`${process.env.NEXT_PUBLIC_STRAPI_API_URL}/api/entertainments`),
fetch(`${process.env.NEXT_PUBLIC_STRAPI_API_URL}/api/food-and-drinks`),
fetch(`${process.env.NEXT_PUBLIC_STRAPI_API_URL}/api/interests`),
fetch(`${process.env.NEXT_PUBLIC_STRAPI_API_URL}/api/personnalities`),
];
const [entertainments, foodAndDrinks, interests, personnalities] = await Promise.all(requests);
return {
props: {
entertainments: (await entertainments.json()).data,
foodAndDrinks: (await foodAndDrinks.json()).data,
interestsAndActivities: (await interests.json()).data,
personnalities: (await personnalities.json()).data,
},
};- J'ai également exploré les différences entre la programmation synchrone et asynchrone, et les avantages et inconvénients de chaque approche :
- Synchrone : Dans une programmation synchrone, les tâches sont exécutées de manière séquentielle. Une tâche doit se terminer avant que la suivante ne commence. Cela signifie que le programme attend la fin de chaque opération avant de passer à la suivante. Ce modèle est plus simple à comprendre et à implémenter, mais peut entraîner des performances réduites si certaines tâches prennent beaucoup de temps à se terminer.
- Asynchrone : Dans une programmation asynchrone, les tâches peuvent être exécutées de manière concurrente. Une tâche peut commencer avant que la précédente ne se termine, et le programme peut continuer à fonctionner pendant que d'autres tâches sont exécutées en arrière-plan. Cela permet d'améliorer les performances et la réactivité des applications, surtout lorsque des opérations d'entrée/sortie ou des appels réseau sont impliqués.
- Pourquoi :
La programmation concurrente est essentielle pour développer des applications performantes et réactives, particulièrement dans des environnements où les tâches longues ou complexes doivent être exécutées sans bloquer l'ensemble du programme. La maîtrise de cette compétence permet de maximiser l'utilisation des ressources du système, d'améliorer l'efficacité des applications et de répondre aux exigences de performance des systèmes modernes.
- Application pratique :
Durant la formation, j'ai réalisé plusieurs projets pratiques, dont un projet notable consistant en une simulation de comportement séquentiel et parallèle. J'ai créé plusieurs threads pour exécuter des tâches spécifiques et utilisé des techniques de synchronisation pour garantir l'intégrité des données partagées. Par exemple, j'ai implémenté un scénario où le thread principal attendait la fin des threads secondaires avant de poursuivre son exécution en utilisant la méthode join(). Cela m'a permis de comprendre l'importance de la synchronisation et de la gestion des threads pour éviter les conditions de course et les interblocages.
- Réflexion personnelle :
La formation sur la programmation concurrente a été une expérience enrichissante et m'a permis de développer des compétences cruciales pour mon avenir professionnel. J'ai appris à gérer des threads de manière efficace et à résoudre les problèmes de concurrence, ce qui m'a préparé à développer des applications robustes et performantes. Cette compétence est particulièrement précieuse dans un contexte où les applications doivent répondre à des exigences de performance de plus en plus élevées, et où la gestion efficace des ressources est essentielle pour le succès des projets logiciels.
Maîtriser la programmation distribuée
- Quoi:
Cette compétence implique la capacité de développer et de gérer des applications qui fonctionnent sur plusieurs ordinateurs connectés en réseau, formant un système distribué. Elle nécessite une compréhension des modèles de communication entre processus, de la gestion de la cohérence des données, du traitement des défaillances, de l'équilibrage de charge et de l'optimisation des performances à travers différents nœuds. La programmation distribuée est essentielle pour créer des systèmes robustes, évolutifs et performants, capables de gérer des volumes de données et de requêtes élevés.
- Comment:
- Résumé de la Présentation sur Apache Kafka pour la Programmation Distribuée (LI + LAB)
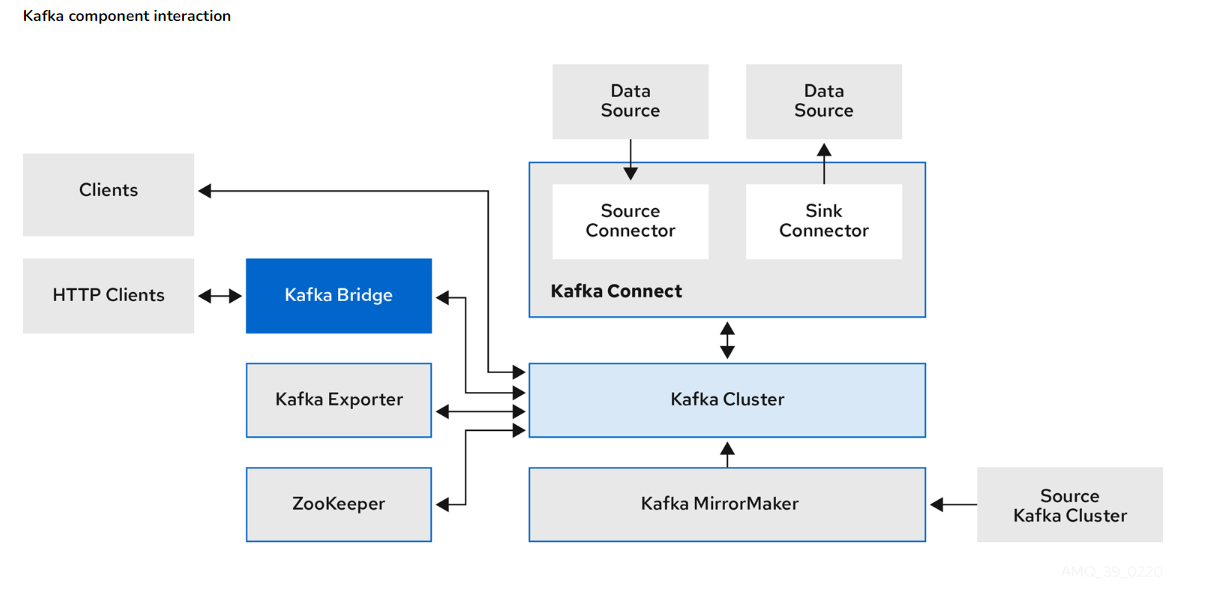 Extrait de LI sur Kafka
Extrait de LI sur Kafka
Qu'est-ce que le Streaming d'Événements ?
Le streaming d'événements (ou "event streaming") est une technologie permettant de capturer et de traiter des flux de données en temps réel. Il est comparé au système nerveux central du corps humain pour les entreprises modernes, automatisées et pilotées par les logiciels. Les données proviennent de diverses sources (bases de données, capteurs, appareils mobiles, etc.) et sont stockées de manière durable pour une récupération ultérieure. Elles peuvent être manipulées en temps réel ou de manière rétrospective.
Utilisations du Streaming d'Événements :
- Transactions financières en temps réel
- Suivi et surveillance des véhicules et des expéditions
- Analyse des données de capteurs IoT
- Interactions clients et commandes
- Surveillance des patients
- Connexion et intégration des données d'entreprise
- Fondations pour les architectures événementielles et les microservices
Qu'est-ce qu'Apache Kafka ?
Apache Kafka est une plateforme de streaming d'événements qui permet de publier, s'abonner, stocker et traiter des flux d'événements de manière continue et fiable. Il combine trois capacités clés :
- Publication et Abonnement : Kafka permet de publier (écrire) et de s'abonner (lire) à des flux d'événements.
- Stockage Durable : Kafka stocke les flux d'événements de manière durable et fiable aussi longtemps que nécessaire.
- Traitement des Événements : Kafka permet de traiter les flux d'événements en temps réel ou rétrospectivement.
Kafka offre ces fonctionnalités dans un environnement distribué, évolutif, tolérant aux pannes et sécurisé.
Fonctionnement de Kafka
Kafka est un système distribué composé de serveurs (brokers et Kafka Connect) et de clients. Les serveurs gèrent le stockage et l'import/export des flux d'événements, tandis que les clients permettent d'écrire des applications distribuées qui lisent et traitent ces flux.
Composants Principaux :
- Cluster Kafka : Ensemble de serveurs exécutant Kafka, répartis sur plusieurs centres de données ou régions cloud.
- Brokers : Serveurs de stockage gérant les flux d'événements.
- Kafka Connect : Serveurs pour l'import/export de données en continu.
Concepts et Terminologie
- Événement : Enregistrement d'un fait (ex. : paiement effectué). Contient une clé, une valeur, un horodatage et des métadonnées optionnelles.
- Producteurs et Consommateurs : Applications clientes publiant (producteurs) ou s'abonnant (consommateurs) aux événements.
- Topics : Organisent et stockent les événements. Partitions réparties sur différents brokers pour la scalabilité.
Avantages de Kafka pour la Programmation Distribuée
- Tolérance aux Pannes : Le cluster Kafka est hautement évolutif et tolérant aux pannes.
- Évolutivité : Kafka permet de gérer de grandes quantités de données en temps réel.
- Durabilité et Fiabilité : Les événements sont stockés durablement, permettant une récupération fiable.
- Flexibilité : Kafka peut être déployé sur du matériel physique, des machines virtuelles, des conteneurs, sur site ou dans le cloud.
- Simplicité et Efficacité : Utilisation efficace des ressources matérielles, simplifiant la gestion des caches et des écritures sur disque.
En conclusion, Apache Kafka est une plateforme robuste et flexible pour le streaming d'événements, offrant des fonctionnalités essentielles pour la programmation distribuée et répondant aux besoins des applications modernes à grande échelle.
- Résumé de la Présentation sur Redis(LI + LAB)
Qu'est-ce que Redis ?
Redis (Remote Dictionary Server) est une base de données en mémoire de type clé-valeur. Contrairement aux autres bases de données en mémoire, Redis prend en charge des structures de données plus complexes comme les listes et les ensembles, permettant des opérations avancées.
Architecture Fondamentale de Redis
- Type Clé-Valeur : Données stockées sous forme de paires clé-valeur où chaque clé est unique.
- Base de Données en Mémoire : Données conservées dans la mémoire RAM pour des opérations de lecture et d'écriture ultra-rapides.
- Écrit en C : Contribue à l'efficacité et à la vitesse de Redis.
Avantages et Désavantages
-
Avantages :
- Vitesse élevée grâce à l'utilisation de la RAM.
- Simplicité de l'architecture clé-valeur.
- Flexibilité avec le support de divers types de données.
-
Désavantages :
- Coût élevé de la mémoire RAM.
- Persistance des données nécessitant une configuration spécifique.
- Évolutivité principalement verticale.
Mécanismes de Persistance
- Fichiers RDB (Redis Database) : Snapshots périodiques des données en mémoire.
- Fichiers AOF (Append Only File) : Journalisation continue des opérations d'écriture.
Mise à l'Échelle
- Clustering Redis : Distribue les données sur plusieurs nœuds pour gérer de grands ensembles de données.
Types de Valeurs Stockées par Redis
- String : Chaîne de caractères simple.
- List : Collection ordonnée de chaînes de caractères.
- Set : Collection non ordonnée de chaînes de caractères uniques.
- Hash : Ensemble de champs associés à leurs valeurs.
- Sorted Set : Ensemble ordonné de chaînes de caractères uniques, trié selon une valeur numérique.
Utilisations Courantes
-
Caches rapides : Amélioration des performances des applications en stockant des données fréquemment accédées.
-
Sessions utilisateur : Gestion des sessions pour les applications web.
-
File d'attente : Gestion de tâches asynchrones.
-
Classements et Leaderboards : Suivi et affichage des scores ou des classements.
-
Pourquoi :
Maîtriser la programmation distribuée est crucial dans le développement de systèmes capables de traiter des volumes de données et des requêtes élevés de manière efficace et fiable. Les systèmes distribués permettent une scalabilité horizontale, assurent une haute disponibilité et améliorent les performances globales des applications. Ils sont essentiels dans les architectures modernes, telles que les microservices et les big data, où la distribution des charges de travail et la tolérance aux pannes sont primordiales.
- Application pratique :
J'ai appliqué mes compétences en programmation distribuée lors d'un petit lab réalisé par un camarade, où j'ai pu tester des technologies comme Apache Kafka et Redis. Cette expérience m'a permis de comprendre comment Kafka peut être utilisé pour le traitement en temps réel des flux de données, en capturant et traitant les informations provenant de diverses sources. Redis a été utilisé pour gérer des caches rapides et la persistance des données, permettant de stocker des sessions utilisateur et des données de classement, assurant des temps de réponse rapides et une gestion efficace des données fréquemment accédées.
- Réflexion personnelle :
Maîtriser la programmation distribuée a été une étape essentielle dans mon développement professionnel. Chaque lab m'a permis de comprendre les défis uniques de la distribution des charges de travail, de la gestion des données et de la tolérance aux pannes. Les technologies comme Apache Kafka et Redis m'ont montré l'importance de choisir les outils appropriés pour répondre aux exigences spécifiques des projets. Ces expériences m'ont convaincu que la programmation distribuée est une compétence incontournable pour tout développeur souhaitant créer des systèmes robustes, évolutifs et performants.
Connaitre les concepts de développement logiciel DevSecOps
- Quoi:
Cette compétence consiste à comprendre et à intégrer les principes de DevSecOps, qui combine le développement (Dev), la sécurité (Sec) et les opérations (Ops) pour créer un processus de développement logiciel plus sûr et plus efficace. Elle inclut la mise en œuvre de pratiques telles que l'intégration continue, la livraison continue, le déploiement automatique, la surveillance en temps réel, et l'intégration de la sécurité à chaque étape du cycle de vie du développement logiciel. Cette approche vise à réduire les risques de sécurité, à accélérer les délais de mise en marché et à améliorer la collaboration entre les équipes.
- Comment:
- Synthèse LI sur DevSecOps – CI/CD
Grâce à l'aide de mes camarades, j'ai pu comprendre le fonctionnement du CI/CD, ainsi que son intégration avec Docker et Kubernetes.
Utilisation de Kubernetes en DevSecOps
-
Prise en main de Kubernetes
- Déploiement d'applications conteneurisées : Kubernetes automatise le déploiement, la mise à l'échelle et la gestion des applications conteneurisées en utilisant des pools de serveurs. Il répond aux défis de la gestion des services distribués sur plusieurs serveurs, motivés par des besoins de répartition géographique, de performances accrues ou de haute disponibilité.
-
Le concept du cluster
- Cluster Kubernetes : Un ensemble de machines (nœuds) sur lesquelles des conteneurs sont exécutés. Les services essentiels tels que kube-apiserver, etcd, kube-scheduler et kube-controller-manager sont regroupés dans le Control Plane, tandis que les Worker nodes hébergent les conteneurs et incluent des services comme kubelet, kube-proxy et le Container Runtime.
- Interaction continue : Cette structure facilite l'interaction continue entre les nœuds et le Control Plane, rendant ainsi la gestion et le déploiement des applications plus efficaces.
-
Sécurité de Kubernetes
- CIS Benchmarks : Normes détaillées pour sécuriser Kubernetes couvrant divers aspects. Utilisation d'outils comme Kube-Bench pour automatiser la vérification de la conformité et Kube-hunter pour identifier les vulnérabilités potentielles.
-
Les objets dans Kubernetes
- Pods : Unité de base pour le déploiement et la gestion des conteneurs sur les Worker nodes. Les Pods peuvent contenir plusieurs conteneurs qui partagent les mêmes ressources réseau et de stockage.
- ReplicaSets : Garantissent qu'un nombre spécifié de répliques identiques de pods est en fonctionnement pour assurer la disponibilité et la tolérance aux pannes.
- Deployments : Déclaration de l'état désiré d'une application, gestion du déploiement et des mises à jour de manière déclarative.
- Services : Abstraction qui définit un ensemble de pods et une politique d'accès stable. Types de services : ClusterIP, NodePort, LoadBalancer, ExternalName.
- Probes : Mécanismes pour vérifier l'état de santé des conteneurs, incluant les probes d'initialisation, de disponibilité et de fiabilité.
-
Tests de lint et de sécurité sur les objets Kubernetes
- KubeLinter : Examine les fichiers YAML des objets Kubernetes pour identifier les erreurs et les mauvaises pratiques.
- Checkov : Analyse de l'infrastructure as code (IaC) pour détecter les problèmes de sécurité et les erreurs de configuration.
-
Culture et connaissance en cybersécurité
- Principes CIA : Confidentialité, Intégrité et Disponibilité sont les bases de la sécurité informatique.
- SIEM : Security Information and Event Management pour l'analyse en temps réel des systèmes de sécurité.
- Principales attaques informatiques : Attaques par reconnaissance, social engineering, phishing, brute force, déni de service (DDoS).
-
Sécurité du développement et bonnes pratiques
- Application de la sécurité au SDLC : Intégration de la sécurité à chaque étape du cycle de vie du développement logiciel (planification, conception, codage, déploiement).
- SSDLC : Secure Software Development Life Cycle pour anticiper les vulnérabilités dès les premières phases du développement.
- TOP 10 de l’OWASP : Liste des dix principales vulnérabilités de sécurité des applications web, telles que l'injection SQL, le Cross-Site Scripting (XSS), et le Broken Authentication.
-
Gestion des événements de l'infrastructure
- Logs : Importance des logs pour la traçabilité, l'analyse des menaces et la conformité aux normes de sécurité.
-
Utilisation de Docker en CI/CD
- Docker : Outil de conteneurisation permettant de créer des conteneurs légers et portables pour déployer des applications de manière cohérente sur différents environnements.
- Images Docker : Contiennent tout ce qui est nécessaire pour exécuter l'application, y compris le code, les bibliothèques et les dépendances.
- Registres d'images : Stockent les images Docker pour être utilisées dans les pipelines CI/CD, par exemple Docker Hub.
-
Intégration de Kubernetes dans CI/CD
- Orchestration des conteneurs : Kubernetes standardise le déploiement des applications conteneurisées, facilitant la gestion des environnements et le déploiement continu.
- Pipeline CI/CD avec Kubernetes : Déploiement automatisé d'applications en utilisant des fichiers de configuration YAML pour définir les ressources Kubernetes.
Ce semestre, j'ai eu l'opportunité de participer à une formation approfondie en DevSecOps, répartie en trois sessions riches en contenu.
J'ai commencé par explorer comment organiser efficacement un environnement SCRUM DevOps sur Microsoft Azure. Cela incluait la gestion des User Stories, des tâches, des sprints, et la création d'un backlog de sprint avec les outils Microsoft. J'ai également appris à évaluer les Story Points, à différencier le temps des Story Points, et à calculer la vélocité à l'aide de graphiques Burndown et Burnup. Cette partie a également couvert comment utiliser les Story Points pour la facturation et l'estimation des coûts dans un cadre AGILE.
Ensuite, j'ai approfondi les fonctionnalités d'Azure DevOps, notamment l'intégration de Git, la mise en place de pipelines CI/CD, et l'application des principes SCRUM dans un environnement DevSecOps.
La formation m'a également permis de plonger dans la philosophie DevSecOps, en particulier le concept de Security by Design et l'importance d'intégrer la sécurité dès le début du cycle de développement. J'ai étudié les méthodes CI/CD pour assurer une intégration et un déploiement continus sécurisés.
En ce qui concerne le contrôle de version avec Git, j'ai appris à organiser les dépôts en fonction des branches, des équipes et des fonctionnalités. La formation a également couvert les tests de sécurité applicative statique (SAST), dynamique (DAST) et interactif (IAST), en détaillant leur portée, les outils à utiliser, et leur intégration dans le processus CI/CD. J'ai examiné les meilleures pratiques et les normes à suivre pour garantir une sécurité robuste, tout en respectant les exigences du RGPD.
Enfin, la présentation des pipelines CI/CD m'a permis de comprendre les défis associés à leur mise en œuvre et de découvrir des solutions et astuces pour les surmonter. Des exemples concrets de pipelines m'ont aidé à visualiser leur application pratique.
- Koloka (Compétence du prochain semestre "Hautement spécialisée")
Dans le cadre du projet Koloka, j'ai eu l'opportunité de mettre en place une pipeline CI/CD (Continuous Integration/Continuous Deployment). Pour ce faire, j'ai créé les fichiers de configuration YAML nécessaires à l'automatisation des différentes étapes du processus de développement et de déploiement.
J'ai utilisé Kubernetes (k8s) pour orchestrer les déploiements et gérer les conteneurs, assurant ainsi la scalabilité et la résilience de l'application. J'ai également intégré GitHub Actions pour automatiser les tests, les builds et les déploiements à chaque modification du code, garantissant ainsi une livraison continue et fiable.
De plus, j'ai utilisé le service Jelastik d'Infomaniak pour héberger et gérer notre infrastructure cloud. Ce service nous a permis de bénéficier d'une plateforme flexible et performante, facilitant la gestion et le déploiement de nos applications.
En résumé, mes contributions au projet Koloka ont inclus :
- Création de fichiers de configuration YAML : Définir les workflows et les pipelines nécessaires pour automatiser les processus de CI/CD.
- Utilisation de Kubernetes (k8s) : Orchestration des conteneurs pour assurer la scalabilité et la résilience de l'application.
- Intégration de GitHub Actions : Automatisation des tests, des builds et des déploiements, permettant une livraison continue et fiable.
- Utilisation du service Jelastik d'Infomaniak : Hébergement et gestion de l'infrastructure cloud, offrant une plateforme flexible et performante.
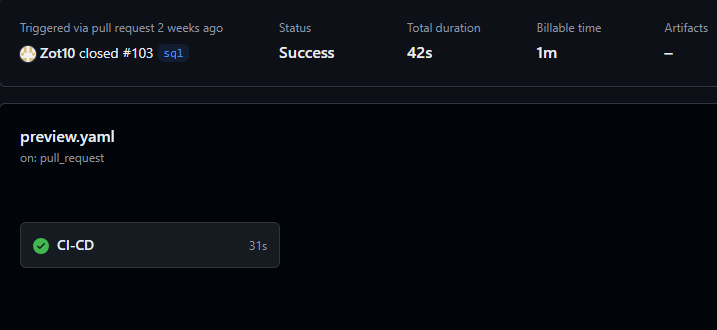 Extrait de github actions
Extrait de github actions
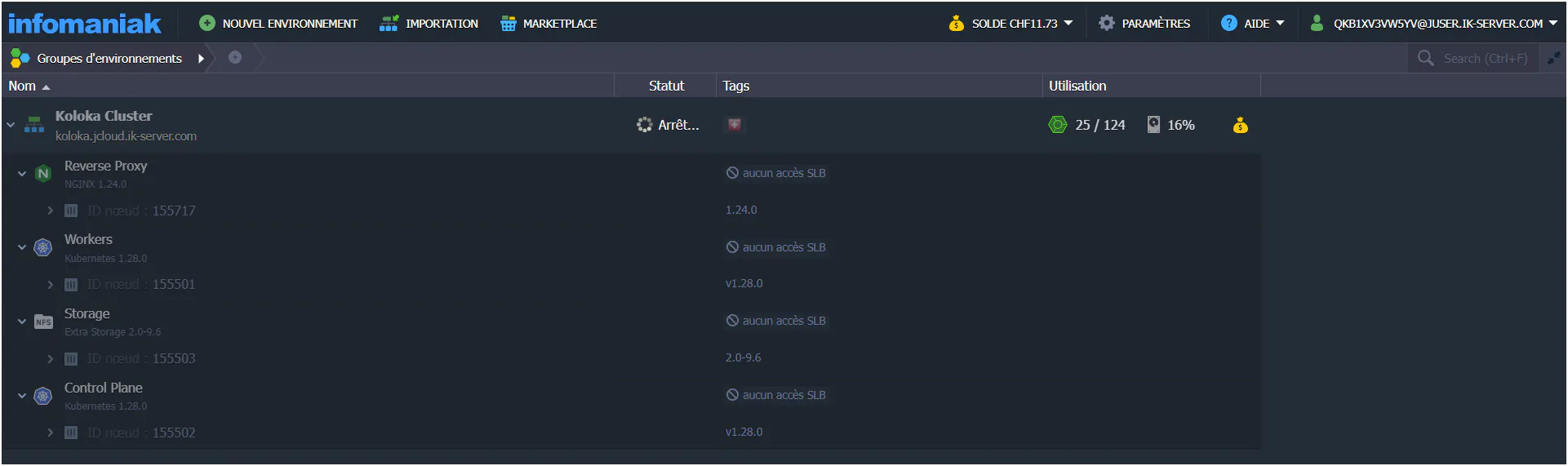 Extrait du service Jelastic d'Infomaniak
Extrait du service Jelastic d'Infomaniak
- LI - AGL: Grâce à la lecture d'un camarade, j'ai pu découvrir et comprendre les concepts des AGL (Atelier de Génie Logiciel) et de l'ALM (Application Lifecycle Management). Cette lecture m'a également permis de mieux saisir le lien entre l'ALM et les pratiques DevOps, enrichissant ainsi mes connaissances et ma capacité à intégrer ces concepts dans la gestion de projets complexes.
 *Extrait schéma ALM, récupéré le 20 juin 2024 au lien suivant : https://www.inflectra.com/Ideas/Topic/Understanding-ALM-Tools.aspx (opens in a new tab) *
*Extrait schéma ALM, récupéré le 20 juin 2024 au lien suivant : https://www.inflectra.com/Ideas/Topic/Understanding-ALM-Tools.aspx (opens in a new tab) *
- Pourquoi :
Comprendre et intégrer les concepts de DevSecOps est crucial pour assurer la sécurité, l'efficacité et la rapidité des processus de développement logiciel. En intégrant la sécurité dès le début du cycle de vie du développement, on peut réduire les risques de vulnérabilités et garantir que les applications sont protégées contre les menaces potentielles. L'automatisation des processus de CI/CD permet de déployer des applications plus rapidement et de manière plus fiable, tout en assurant une qualité constante. De plus, l'utilisation de conteneurs et de plateformes comme Kubernetes permet de gérer efficacement les ressources et de garantir la scalabilité et la résilience des applications.
- Application pratique :
En appliquant ces concepts, j'ai pu assurer la mise en place de pipelines CI/CD efficaces et sécurisés dans le cadre de projets réels comme Koloka. L'utilisation de Kubernetes et de Docker a permis de standardiser et de simplifier les déploiements, tout en assurant une gestion optimale des ressources. L'intégration de GitHub Actions a facilité l'automatisation des tests et des déploiements, garantissant une livraison continue de qualité. Grâce à ces pratiques, j'ai pu améliorer la sécurité, la rapidité et l'efficacité des processus de développement, tout en répondant aux exigences spécifiques des projets.
- Réflexion personnelle :
Ma formation et mes expériences en DevSecOps m'ont permis de comprendre l'importance de l'intégration de la sécurité et de l'automatisation dans le développement logiciel. Chaque projet m'a enseigné l'importance de la rigueur et de la précision dans la configuration des pipelines CI/CD et la gestion des conteneurs. Les défis rencontrés m'ont appris à être adaptable et à chercher constamment des solutions pour améliorer les processus. En fin de compte, ces compétences me permettent de contribuer de manière significative à la création de logiciels sécurisés et efficaces, tout en répondant aux attentes des parties prenantes.
Être capable de concevoir et d’exploiter des ressources, services et fonctionnalités d’une infrastructure virtuelle (cloud,…)
- Quoi :
Cette compétence implique la capacité de concevoir et de gérer les ressources, services et fonctionnalités offerts par une infrastructure virtuelle, telle que le cloud computing. Elle comprend la planification, la configuration et l'optimisation de services tels que le stockage, les réseaux, les serveurs virtuels, et les applications distribuées. Cela inclut également la gestion de la sécurité, la surveillance des performances, la mise en œuvre de la haute disponibilité, la reprise après sinistre et l'élasticité pour s'adapter à des charges de travail variables.
- Comment:
- Projet Koloka
Dans le cadre du projet Koloka, j'ai eu l'opportunité de mettre en place une pipeline CI/CD (Continuous Integration/Continuous Deployment). Pour ce faire, j'ai créé les fichiers de configuration YAML nécessaires à l'automatisation des différentes étapes du processus de développement et de déploiement.
J'ai utilisé Kubernetes (k8s) pour orchestrer les déploiements et gérer les conteneurs, assurant ainsi la scalabilité et la résilience de l'application. J'ai également intégré GitHub Actions pour automatiser les tests, les builds et les déploiements à chaque modification du code, garantissant ainsi une livraison continue et fiable.
De plus, j'ai utilisé le service Jelastic d'Infomaniak pour héberger et gérer notre infrastructure cloud. Ce service m'a permis de bénéficier d'une plateforme flexible et performante, facilitant la gestion et le déploiement des applications.
En résumé, mes contributions au projet Koloka ont inclus :
- Utilisation de Jelastic d'Infomaniak : J'ai utilisé le service Jelastic pour héberger et gérer notre infrastructure cloud, bénéficiant ainsi d'une plateforme flexible et performante.
- Pipeline CI/CD : J'ai mis en place une pipeline de CI/CD (Continuous Integration/Continuous Deployment) en créant des fichiers de configuration YAML pour automatiser les étapes du processus de développement et de déploiement.
- Kubernetes (k8s) : J'ai orchestré les déploiements et géré les conteneurs, assurant la scalabilité et la résilience de l'application.
- GitHub Actions : J'ai intégré GitHub Actions pour automatiser les tests, les builds et les déploiements, garantissant une livraison continue et fiable.
- Résultats : Grâce à cette mise en place, le projet Koloka bénéficie d'un processus de développement plus rapide et d'un déploiement plus sécurisé, tout en réduisant les risques d'erreurs humaines.
- Lecture et pratique individuelle sur les services AWS En parallèle, j'ai mené une étude approfondie sur les différents services cloud d'AWS (Amazon Web Services). Cette étude théorique a été complétée par des exercices pratiques qui m'ont permis de mettre en œuvre concrètement les concepts appris.
Les services AWS que j'ai étudiés et mis en pratique incluent :
-
Elastic Beanstalk : J'ai déployé et géré des applications web sans avoir à gérer l'infrastructure sous-jacente.
-
EC2 (Elastic Compute Cloud) : J'ai créé et géré des serveurs virtuels (instances) pour héberger diverses applications.
-
RDS (Relational Database Service) : J'ai configuré, exploité et mis à l'échelle des bases de données relationnelles dans le cloud.
-
S3 (Simple Storage Service) : J'ai stocké et récupéré n'importe quelle quantité de données à tout moment, de n'importe où sur le web.
-
Pourquoi :
La compétence de concevoir et d’exploiter des infrastructures virtuelles est cruciale car elle permet aux entreprises de bénéficier de la flexibilité, de la scalabilité et de l'efficacité offertes par le cloud computing. Elle réduit les coûts d'infrastructure, améliore la gestion des ressources et permet une réponse rapide aux besoins changeants des utilisateurs. De plus, la gestion efficace des ressources cloud garantit la sécurité, la haute disponibilité et la résilience des services, essentiels dans un environnement commercial compétitif et en constante évolution.
- Application pratique :
En appliquant cette compétence, j'ai pu améliorer significativement l'efficacité et la performance des projets sur lesquels j'ai travaillé. Par exemple, dans le projet Koloka, l'utilisation de Jelastic et de Kubernetes a permis une gestion optimisée des ressources, une meilleure résilience des applications et une scalabilité facile. Bien que je n'aie pas utilisé les services AWS dans des projets concrets, l'étude et la mise en pratique de leur création m'ont fourni une base solide pour comprendre les principes du cloud computing et être prêt à les utiliser lorsque nécessaire.
- Réflexion personnelle :
Développer la compétence de gestion des infrastructures virtuelles a été une expérience très enrichissante. J'ai appris à utiliser des technologies avancées pour gérer des ressources complexes et à mettre en œuvre des solutions qui répondent aux besoins réels des entreprises. Les projets pratiques m'ont permis de comprendre l'importance de l'automatisation, de la scalabilité et de la sécurité dans le déploiement des applications. En outre, cette compétence m'a donné la confiance nécessaire pour aborder des projets plus ambitieux et m'a montré l'importance de l'apprentissage continu dans le domaine des technologies de l'information. En somme, cette expérience a renforcé ma conviction que la maîtrise des infrastructures cloud est essentielle pour réussir dans le domaine de l'informatique de gestion.