Compétence B3
Connaître les principes de continuité du business
- Quoi :
Cette compétence englobe la compréhension des principes et des pratiques nécessaires pour assurer la continuité des activités commerciales en cas de perturbation majeure. Elle inclut la planification de la continuité d'activité (PCA) et la gestion de la reprise après sinistre (DRP), l'identification des processus critiques, l'évaluation des risques, et le développement de stratégies pour maintenir les opérations essentielles. Cela nécessite également la mise en place de systèmes de sauvegarde, de redondance des données et de solutions de reprise rapide pour minimiser l'impact sur l'entreprise et garantir une reprise rapide et efficace.
- Comment :
- Grâce à la lecture d'un camarade, j'ai pu approfondir ma compréhension des systèmes de management de la continuité d’activité (SMCA) et des plans de continuité d’activité (PCA). Voici les points les plus importants que j'ai pu retenir et intégrer :
1.1 Normes et Méthodologies :
- ISO 22301 et ISO 27001 : J'ai appris à connaître ces normes qui fournissent un cadre structuré pour gérer et sécuriser les informations critiques d'une entreprise. Ces normes aident à anticiper et prévenir les incidents perturbateurs, garantissant ainsi la continuité des activités. La compréhension de ces normes m'a permis de voir l'importance de la standardisation et de la réglementation pour maintenir la sécurité et l'efficacité des opérations.
1.2 Méthodologies Diverses :
- DRII, BCI, ITIL, COBIT 2019 : J'ai exploré différentes approches et méthodologies reconnues pour leur efficacité dans la gestion de la continuité des activités. DRII et BCI m'ont montré l'importance de la préparation et de la réponse aux incidents, tandis que ITIL et COBIT 2019 m'ont permis de comprendre comment intégrer la résilience dans les services informatiques et la gouvernance des systèmes d'information.
1.3 Système de Management de la Continuité d’Activité (SMCA) :
- Analyse des Risques et Cycle PDCA : J'ai appris à identifier et évaluer les menaces potentielles et à utiliser le cycle PDCA (Plan-Do-Check-Act) pour une amélioration continue du SMCA. Cela m'a montré comment les entreprises peuvent rester proactives et prêtes à gérer les incidents perturbateurs tout en maintenant l'efficacité de leurs opérations.
1.4 Stratégies de Continuité d'Activité :
- Diversification, Réplication, Sites de Repli : J'ai exploré des stratégies telles que la diversification des ressources, la réplication des données et l'utilisation de sites de repli pour garantir que les opérations critiques puissent continuer en cas de perturbation. J'ai compris que ces stratégies sont essentielles pour réduire les risques et assurer la continuité des opérations dans différentes situations de crise.
1.5 Plans de Continuité d'Activité (PCA) :
- Plans d'Urgence, Plans de Reprise après Sinistre (PRAS) : J'ai étudié la structure des PCA, qui incluent des plans d'urgence pour assurer la sécurité immédiate et des PRAS pour la restauration des opérations normales après un incident. Ces plans m'ont montré l'importance de la préparation et de la planification détaillée pour faire face aux crises de manière efficace.
1.6 Bilan d’Impact sur les Activités (BIA) :
- Évaluation des Répercussions et Objectifs de Reprise : J'ai appris à évaluer les répercussions potentielles des perturbations sur les opérations et à identifier les activités critiques, ainsi que les objectifs de reprise (RTO) et de récupération (RPO). Cette évaluation est cruciale pour établir des priorités et des stratégies de reprise adaptées aux besoins de l'entreprise.
-
- Grâce à une autre lecture réalisée par un camarade, j'ai pu approfondir davantage ma compréhension des plans de continuité d’activité (PCA) et de reprise après sinistre. Voici les points les plus importants :
2.1 Plan de Continuité d’Activité (PCA) :
- Structure et Étapes du PCA : J'ai compris comment structurer un PCA documenté pour répondre efficacement aux perturbations, en identifiant les incidents, en mobilisant les ressources nécessaires, et en assurant la reprise des opérations normales. Cette approche m'a montré l'importance de la réactivité et de la gestion structurée des crises.
2.2 Procédures PCA :
- Procédures Détaillées et Adaptation : J'ai appris que les PCA nécessitent des procédures détaillées pour chaque étape clé, de l'activation à la gestion de la charge de travail, et qu'il est crucial d'adapter ces procédures aux besoins spécifiques de chaque département impliqué.
2.3 Plan de Reprise d’Activité (PRA) :
- Structure et Stratégies de Reprise : J'ai étudié comment structurer un PRA, en incluant des objectifs clairs, une équipe dédiée, et des stratégies de reprise détaillées. Cela inclut également la communication, les ressources techniques et la maintenance pour garantir une reprise rapide et efficace.
2.4 Gestion des Incidents et Crises :
- Détection à la Résolution : J'ai appris l'importance de gérer les incidents de leur détection à leur résolution, avec une documentation précise pour l'analyse et l'amélioration continue. La gestion efficace des crises nécessite une compréhension des interdépendances entre différents plans et des critères clairs d'activation et de gestion des incidents.
2.5 Maintien en Conditions Opérationnelles (MCO) :
- Processus et Types de Maintenance : J'ai compris les processus nécessaires pour garantir la disponibilité, la fiabilité et la performance des équipements et systèmes critiques, en incluant différents types de maintenance comme la préventive, corrective, prédictive, conditionnelle, et de réparation.
Grâce à l'aide d'un collègue et à son lab, j'ai pu approfondir mes connaissances sur la gestion de la reprise après sinistre et la continuité des activités. J'ai découvert comment mettre en œuvre diverses mesures et technologies pour assurer la continuité des activités d'une entreprise, même en cas de sinistre.
J'ai simulé plusieurs scénarios de sinistre et j'ai expliqué comment les gérer efficacement en utilisant Kubernetes et ses opérateurs. Cela m'a permis de mieux comprendre les mécanismes de résilience et de récupération des services critiques, en garantissant une haute disponibilité et en minimisant les interruptions.
Ces simulations m'ont permis de voir concrètement comment Kubernetes peut automatiser la récupération des applications, réallouer les ressources de manière dynamique et assurer la redondance des données. En appliquant ces techniques, j'ai pu démontrer une approche proactive et robuste pour la gestion des sinistres, contribuant ainsi à la résilience globale de l'infrastructure IT de l'entreprise.
- Pourquoi :
Connaître les principes de continuité du business est essentiel pour assurer la pérennité des opérations d'une entreprise face à des perturbations imprévues. Cela permet de minimiser les interruptions, de protéger les actifs critiques et de maintenir la confiance des clients et des partenaires. En étant préparé à gérer des incidents et des crises, une entreprise peut non seulement survivre à des événements perturbateurs, mais aussi en ressortir plus résiliente. Cette compétence assure également que l'entreprise peut se conformer aux réglementations et aux standards de l'industrie, ce qui renforce sa crédibilité et sa compétitivité.
- Application pratique :
Même si je n'ai pas eu l'occasion d'appliquer ces principes dans un contexte réel, j'ai pu simuler des scénarios de sinistre dans un environnement de laboratoire. Par exemple, en utilisant Kubernetes et ses opérateurs, j'ai simulé diverses situations de crise et appris à automatiser la récupération des applications, à réallouer les ressources de manière dynamique et à assurer la redondance des données. Ces simulations m'ont permis de mieux comprendre les mécanismes de résilience et de récupération des services critiques, en garantissant une haute disponibilité et en minimisant les interruptions. Bien que ces expériences soient virtuelles, elles m'ont préparé à appliquer ces principes de manière concrète dans des contextes professionnels futurs.
- Réflexion personnelle :
Comprendre et appliquer les principes de continuité du business dans des simulations de laboratoire a été une expérience enrichissante qui m'a permis de voir l'importance de la préparation et de la résilience dans un environnement professionnel. Chaque simulation de sinistre m'a montré la valeur de l'anticipation et de la réactivité face aux crises. J'ai appris que la clé de la continuité du business réside dans une planification minutieuse, une évaluation rigoureuse des risques et une adaptation constante aux nouvelles menaces. Cette compétence m'a donné une vision plus claire de l'importance de la stabilité et de la fiabilité dans le monde des affaires, et je suis convaincu que cela me prépare mieux à faire face aux défis futurs et à contribuer de manière significative à la résilience des entreprises.
Savoir prendre en compte les enjeux liés à la durabilité
- Quoi :
Cette compétence consiste à intégrer et à prioriser les considérations de durabilité dans les décisions et les actions. Elle implique la compréhension des impacts environnementaux, sociaux et économiques des activités et la mise en œuvre de pratiques qui favorisent la responsabilité écologique, l'équité sociale et la viabilité économique à long terme. Cela inclut l'adoption de technologies et de méthodes éco-efficaces, la réduction des déchets, l'utilisation rationnelle des ressources, ainsi que la promotion de l'éthique et de la transparence dans les pratiques commerciales.
- Comment :
- Koloka
-
Choix Initial : AWS : Au début du projet Koloka, j'avais choisi Amazon Web Services (AWS) comme fournisseur de services cloud pour ses performances et sa scalabilité. Cependant, malgré leurs efforts récents en matière de durabilité, les centres de données d'AWS sont encore majoritairement alimentés par des sources d'énergie traditionnelles, ce qui peut avoir un impact environnemental considérable.
-
Transition vers Infomaniak : Conscient de l'importance de la durabilité, j'ai décidé de migrer notre infrastructure chez Infomaniak, un fournisseur de services cloud suisse réputé pour ses pratiques respectueuses de l'environnement. Infomaniak utilise exclusivement de l'énergie renouvelable pour alimenter ses centres de données, réduit l'empreinte carbone avec des systèmes de refroidissement avancés et est certifié ISO 14001. Leur engagement dans des projets écologiques et communautaires assure que nos opérations soutiennent des pratiques respectueuses de l'environnement.
Grâce à la lecture du document sur le cloud durable, j'ai pu identifier plusieurs pratiques et stratégies essentielles pour prendre en compte les enjeux liés à la durabilité dans le domaine de l'informatique en nuage. Voici les éléments les plus importants :
-
Importance de la Durabilité : La demande croissante des services numériques et la sensibilisation aux problèmes environnementaux nécessitent le développement durable. Il s'agit de minimiser l'empreinte environnementale des services de cloud computing en utilisant des énergies renouvelables, optimisant la consommation énergétique des data centers, et réduisant les émissions de carbone.
-
Consommation du Cloud : Les centres de données représentent environ 2 % de la demande énergétique mondiale, avec une majorité de cette énergie provenant du charbon et de l'énergie nucléaire. Le refroidissement des centres de données représente une part importante de la consommation énergétique totale.
-
Comparaison Services Cloud vs Datacenter Hérités : Les services cloud maximisent l’utilisation des serveurs, réduisent les serveurs inactifs, utilisent des sources d’énergie renouvelable, et bénéficient d’économies d’échelle. Techniques de virtualisation et de répartition de charge garantissant une utilisation efficace des serveurs.
-
Bonnes Pratiques pour un Cloud Durable : Sélection de la région avec une faible empreinte carbone, utilisation de microservices, de conteneurs, et d'architectures orientées messages, mise en place de mécanismes de cache, ajustement de la taille des VM, surveillance et suppression des ressources inutilisées, utilisation des GPU pour les tâches spécifiques et activation de la mise à l’échelle automatique.
-
Meilleures Pratiques des Fournisseurs de Serveurs Cloud :
- Microsoft Azure : Engagement envers les énergies renouvelables avec un objectif de 100 % d'énergie renouvelable d'ici 2025, initiatives de reboisement, gestion de l'eau, et foresterie urbaine.
- AWS : Utilisation de matériaux à faible empreinte carbone dans la construction des centres de données, investissements dans des technologies innovantes pour décarboniser les centres de données.
- Infomaniak : Utilisation exclusive d'énergie renouvelable et de systèmes de refroidissement innovants sans climatisation, production d'énergie solaire, prolongation de la durée de vie des serveurs, engagement envers des initiatives environnementales et sociales.
-
Pourquoi :
Prendre en compte les enjeux liés à la durabilité est crucial pour garantir un avenir où les ressources naturelles sont utilisées de manière responsable et où les impacts environnementaux sont minimisés. En intégrant des pratiques durables, les entreprises peuvent non seulement réduire leur empreinte écologique, mais aussi améliorer leur image de marque, se conformer aux réglementations environnementales, et attirer des clients soucieux de l'environnement. De plus, la durabilité économique et sociale assure une viabilité à long terme et favorise une société plus équitable et responsable.
- Application pratique :
En appliquant cette compétence, j'ai pu faire des choix technologiques plus responsables et durables. Par exemple, la transition de AWS à Infomaniak a permis de réduire significativement l'empreinte carbone de notre infrastructure informatique. Ce changement a également sensibilisé notre équipe aux pratiques écologiques et a encouragé d'autres décisions responsables, comme l'optimisation de la consommation énergétique et la gestion efficace des ressources informatiques. Grâce à ces actions, nous avons non seulement contribué à la protection de l'environnement, mais aussi amélioré la durabilité économique de notre projet en réduisant les coûts à long terme.
- Réflexion personnelle :
Intégrer les enjeux liés à la durabilité dans mes décisions a été une expérience enrichissante et éducative. Cela m'a appris l'importance de considérer non seulement les avantages immédiats, mais aussi les impacts à long terme de nos actions. La transition vers des pratiques plus durables m'a sensibilisé à l'importance de la responsabilité écologique et m'a incité à poursuivre cette voie dans tous les aspects de ma vie professionnelle et personnelle. J'ai réalisé que chaque choix que nous faisons peut avoir un impact significatif sur notre environnement et notre société, et je suis désormais déterminé à continuer à promouvoir et à adopter des pratiques durables dans toutes mes futures entreprises.
Etre capable d’informatiser les processus métier des Organisations
- Quoi :
Cette compétence implique la capacité de transformer et d'automatiser les processus métier d'une organisation en utilisant des solutions informatiques. Elle nécessite une compréhension approfondie des opérations et des flux de travail de l'organisation, ainsi que la capacité d'identifier les points où l'informatisation peut apporter des améliorations en termes d'efficacité, de précision et de vitesse. Cela comprend la conception, le développement et l'intégration de systèmes logiciels, l'optimisation des bases de données, l'implémentation de l'intelligence artificielle et de l'automatisation des processus robotisés (RPA) pour réduire les tâches manuelles et les erreurs, tout en améliorant la qualité et la performance des processus métier.
- Comment :
- Réalisation d'un diagramme BPMN : J'ai créé un diagramme BPMN (Business Process Model and Notation) avec un collègue pour représenter le processus d'une application mobile. Ce diagramme montre comment l'application gère la récupération et la mise à jour des données. Voici un extrait du schéma BPMN :
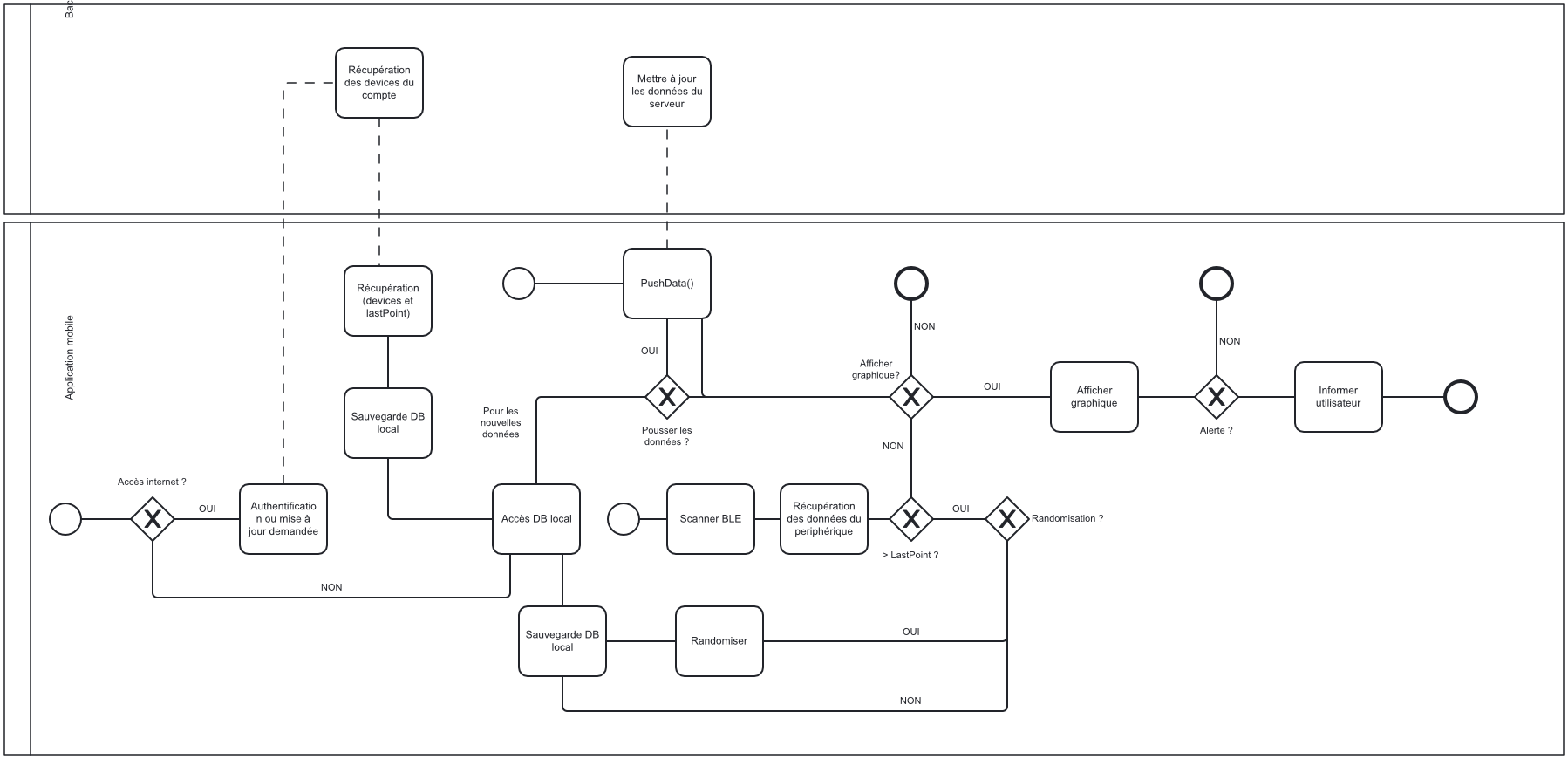 Extrait schéma BPMN
Extrait schéma BPMN
Cette activité m'a permis de comprendre et de visualiser les différents processus métier impliqués et d'identifier les opportunités d'automatisation et d'amélioration.
- Pourquoi :
L'informatisation des processus métier est essentielle pour les organisations modernes car elle permet d'améliorer l'efficacité opérationnelle, de réduire les coûts et d'augmenter la précision des opérations. En automatisant les tâches manuelles et répétitives, les entreprises peuvent se concentrer sur des activités à plus forte valeur ajoutée, augmenter leur productivité et offrir un meilleur service à leurs clients. De plus, l'informatisation permet une meilleure gestion des données et une prise de décision plus éclairée grâce à l'analyse des informations en temps réel. En fin de compte, cela conduit à une plus grande compétitivité sur le marché.
- Application pratique :
L'application pratique de cette compétence s'est manifestée à travers la réalisation du diagramme BPMN pour une application mobile. Ce diagramme a permis de visualiser et d'optimiser le processus de récupération et de mise à jour des données, réduisant ainsi les délais et les erreurs. La création de ce diagramme a servi de base pour proposer des améliorations et des automatisations potentielles, améliorant ainsi l'efficacité du flux de travail.
- Réflexion personnelle :
La réalisation du diagramme BPMN m'a offert une perspective précieuse sur l'importance de la modélisation des processus métier avant de proposer des solutions d'informatisation. Cette expérience m'a appris à analyser de manière critique les processus existants et à identifier les points faibles où l'automatisation pourrait apporter des bénéfices significatifs. En travaillant sur ce projet, j'ai développé une meilleure compréhension des dynamiques des processus métier et de l'impact positif que l'informatisation peut avoir sur la performance organisationnelle. Cette compétence est devenue un atout majeur dans ma capacité à contribuer à l'efficacité et à la compétitivité des organisations.
Être capable d’exploiter un réseau dans un environnement de haute disponibilité (sa mise en œuvre est développée en S1)
- Quoi :
Cette compétence implique la capacité de gérer et de maintenir un réseau informatique dans un environnement nécessitant une haute disponibilité. Elle implique la mise en place et l'exploitation de solutions technologiques qui garantissent que le réseau est toujours opérationnel et performant, même en cas de défaillances partielles ou de demandes de service élevées. Cela inclut la configuration de systèmes de redondance, comme le clustering, les réseaux de distribution de contenu (CDN), et les basculements automatiques, ainsi que l'implémentation de protocoles de surveillance et d'alerte en temps réel pour détecter et résoudre rapidement les problèmes. La compétence requiert également une familiarité avec les technologies et les pratiques de sécurisation réseau pour protéger contre les interruptions et les menaces externes.
- Comment :
- LI AWS : La gestion des instances EC2 et la mise en œuvre de solutions de sauvegarde et de restauration m'ont préparé à exploiter des réseaux dans des environnements de haute disponibilité, assurant ainsi une performance optimale et une résilience accrue.
- Projet Koloka
Utilisation de Docker : Dans le projet Koloka, j'ai utilisé Docker pour containeriser Strapi, un CMS open source. Cette approche garantit que Strapi fonctionne de manière identique dans tous les environnements, facilitant ainsi le déploiement et la maintenance.
FROM node:20.10.0-alpine as build
# Installing libvips-dev for sharp Compatability
RUN apk update && apk add --no-cache build-base gcc autoconf automake zlib-dev libpng-dev vips-dev git > /dev/null 2>&1
ARG NODE_ENV=production
ENV NODE_ENV=${NODE_ENV}
WORKDIR /opt/
COPY ./package.json ./package-lock.json ./
RUN npm install -g node-gyp
RUN npm config set fetch-retry-maxtimeout 600000 -g && npm install --only=production
ENV PATH /opt/node_modules/.bin:$PATH
WORKDIR /opt/app
COPY ./ .
RUN npm run build
FROM node:20.10.0-alpine
RUN apk add --no-cache vips-dev
ARG NODE_ENV=production
ENV NODE_ENV=${NODE_ENV}
WORKDIR /opt/
COPY --from=build /opt/node_modules ./node_modules
WORKDIR /opt/app
COPY --from=build /opt/app ./
ENV PATH /opt/node_modules/.bin:$PATH
RUN chown -R node:node /opt/app
USER node
EXPOSE 1337
CMD ["npm", "run", "start"]Orchestration avec Kubernetes (K8s) : J'ai déployé et géré le conteneur Docker de Strapi à l'aide de Kubernetes, ce qui m'a permis de bénéficier de fonctionnalités comme l'auto-scaling, la gestion des mises à jour sans interruption de service, et la tolérance aux pannes.
Fichier déploiement Kubernetes :
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.preview.fullname }}
namespace: {{ .Values.preview.namespace }}
spec:
selector:
matchLabels:
app: {{ .Values.preview.fullname }}
template:
metadata:
labels:
app: {{ .Values.preview.fullname }}
spec:
imagePullSecrets:
- name: {{ .Values.preview.ghcr.secret.name }}
containers:
- name: {{ .Values.preview.fullname }}
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
imagePullPolicy: {{ .Values.image.pullPolicy }}
ports:
- containerPort: {{ .Values.preview.service.port }}
resources:
requests:
cpu: "2000m"
memory: "2048Mi"
limits:
memory: "4096Mi"
livenessProbe:
httpGet:
path: /health
port: {{ .Values.preview.service.port }}
initialDelaySeconds: 15
periodSeconds: 20
readinessProbe:
httpGet:
path: /health
port: {{ .Values.preview.service.port }}
initialDelaySeconds: 5
periodSeconds: 10Monitoring et Scaling : J'ai mis en place des outils de monitoring pour surveiller l'état de Strapi et des ressources du cluster Kubernetes, permettant de détecter et de répondre rapidement à tout problème. J'ai également configuré des règles de scaling automatique pour ajuster les ressources en fonction de la demande.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: {{ .Values.preview.hpa.name }}
namespace: {{ .Values.preview.namespace }}
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {{ .Values.preview.fullname }}
minReplicas: {{ .Values.preview.hpa.minReplicas }}
maxReplicas: {{ .Values.preview.hpa.maxReplicas }}
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: {{ .Values.preview.hpa.cpu.averageUtilization }}
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: {{ .Values.preview.hpa.memory.averageUtilization }} Extrait de l'IDE du fichier Chart
Extrait de l'IDE du fichier Chart
-
deployment.yaml : Ce fichier est crucial car il définit le déploiement de vos conteneurs Docker sur Kubernetes. Il spécifie le nombre de réplicas, les configurations des pods, et les images Docker à utiliser.
-
service.yaml : Ce fichier configure les services Kubernetes, définissant comment les pods sont exposés et accessibles au sein du cluster ou depuis l'extérieur. Il est essentiel pour comprendre comment le trafic est dirigé vers vos applications.
-
hpa.yaml : Ce fichier configure le Horizontal Pod Autoscaler, qui est important pour la gestion de la scalabilité automatique de vos applications en fonction de la charge.
-
database.yaml et database-secret.yaml : Ces fichiers configurent la base de données utilisée par votre application, y compris les secrets nécessaires pour l'accès sécurisé. Ils montrent comment vous gérez la persistance des données et la sécurité.
-
namespace.yaml : Ce fichier définit les namespaces utilisés dans votre cluster Kubernetes, permettant une organisation et une isolation efficaces des ressources.
- Pourquoi :
Exploiter un réseau dans un environnement de haute disponibilité est crucial pour garantir que les services et applications restent opérationnels et accessibles en permanence. Dans le projet Koloka, l'utilisation de Docker et Kubernetes assure que les services back-end (Strapi) sont résilients, évolutifs et faciles à déployer. La haute disponibilité améliore l'expérience utilisateur en minimisant les interruptions de service, renforce la fiabilité et la performance des systèmes, et assure une meilleure gestion des ressources, ce qui est essentiel dans un environnement de production.
- Application pratique :
Dans le projet Koloka, j'ai utilisé Docker pour containeriser Strapi, assurant ainsi une déploiement et une maintenance simplifiés. Kubernetes a été utilisé pour orchestrer les conteneurs, offrant des fonctionnalités essentielles pour la haute disponibilité, comme l'auto-scaling et la tolérance aux pannes. Le front-end déployé sur Vercel a permis une livraison rapide et fiable des mises à jour. Ensemble, ces technologies ont permis de créer un environnement robuste et hautement disponible, garantissant que les utilisateurs de Koloka bénéficient d'une expérience continue et sans interruption.
- Réflexion personnelle :
Travailler sur le projet Koloka et implémenter des technologies comme Docker, Kubernetes et Vercel m'a permis de développer une compréhension profonde de l'importance de la haute disponibilité dans les environnements de production. J'ai appris à configurer des systèmes résilients, à gérer efficacement les ressources et à anticiper les problèmes potentiels. Ces compétences sont essentielles pour garantir que les services restent opérationnels et performants, même en cas de défaillance de certaines parties du système. Cette expérience m'a également montré l'importance du monitoring et de la gestion proactive des systèmes pour maintenir une haute disponibilité.